6. Load Invoices Historical data
This tutorial is a part of the series - Guided set up.
Invoices - API Documentation
In the last tutorial we had set up the data pipeline for invoices. The daily pipeline will take care of loading the data going forward. This tutorial will help us load the the historical invoice data for our analysis.
Pipeline Requirements
Pipeline Schedule - Run it only once and load the data for 2022 and 2023.
Data fetch strategy: We want to fetch all the Invoice records that have been created or modified between 1st Jan 2022 and 31st Dec 2023. The historical load will follow the same dedupe strategy as our invoices pipeline. We will be loading the historical data using invoices pipeline set up in the previous tutorial
Data Schema requirements: The API response might have evolved over time. Records from 2022 might be missing a few fields as compared to 2023. The schema evolution should be handled automatically.
Data Storage
Azure Blob - In the Azure blob create a folder for Invoices. Within Invoices folder create a folder for every day's data run.
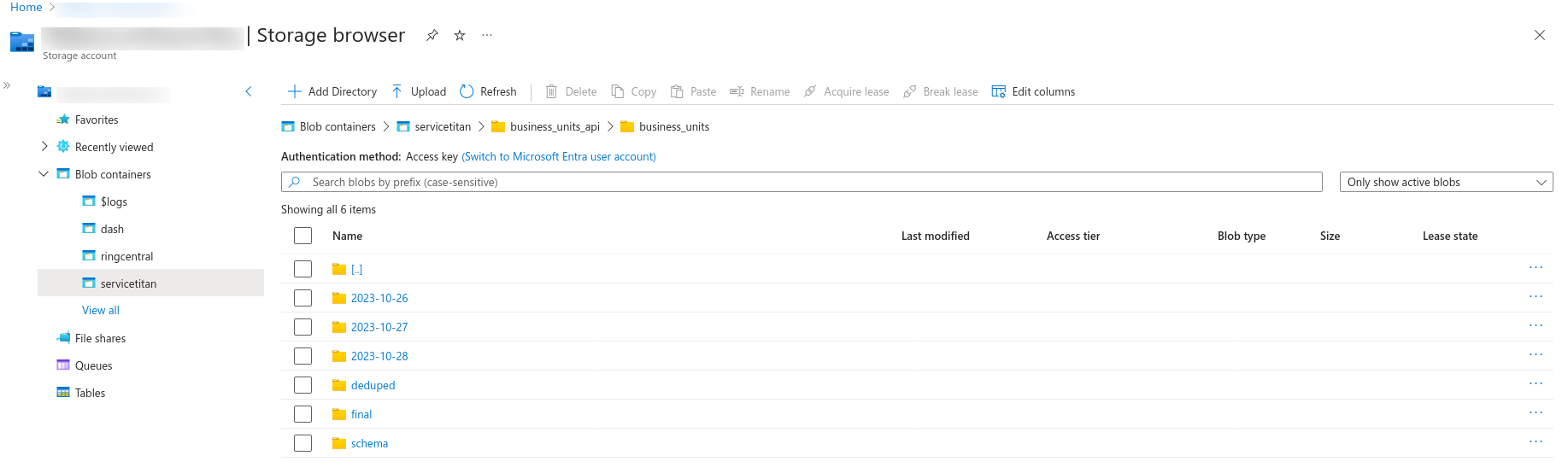
AzureSQL - Create a new table - "invoices" in "servicetitan" schema and write the data to it.
Historical load set up
Our invoices pipeline takes a field - "modifiedOn" as a parameter. The parameter value is provided to the pipeline using a variable - "yesterday".
If our variable has a value - 01-01-2022 then the pipeline will load the data for 1st Jan 2022, if the variable value is 02-01-2022 then the pipeline will load the data for 2nd Jan 2022 and so on.
If we can submit a pipeline for each of the dates starting from 1st Jan 2022 to 31st Dec 2023, this will help us load the historical data.
In order to run historical load navigate to your Integrations -> {{Your integration}} -> Invoices -> three dots to the extreme right.
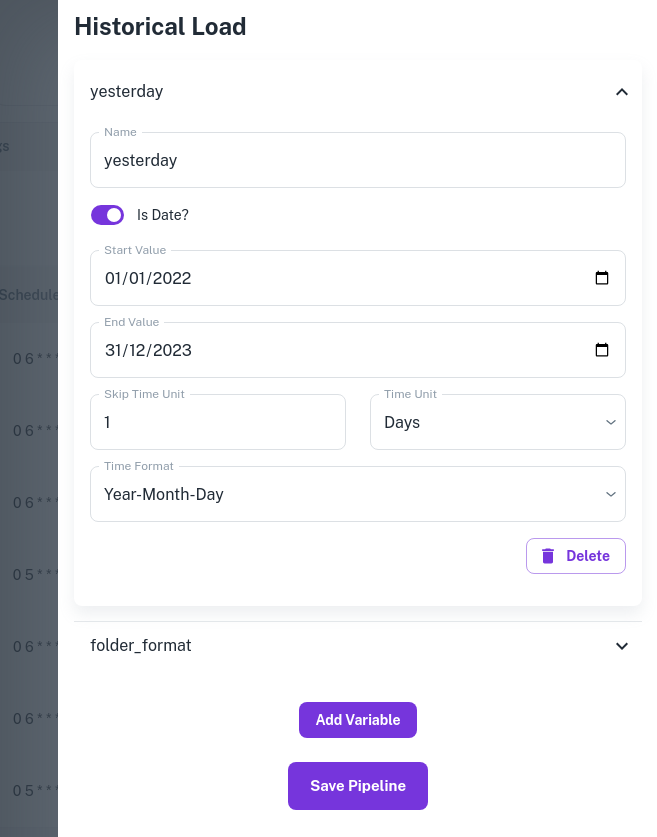
- A new blade will open listing down the variables in your pipeline. Here we have "yesterday" and "folder_format" variables.
Select the "yesterday" variable and fill in the values as shown.
Skip Time Unit is 1 day. This implies ELT Data will submit a pipeline run for each of dates between 1st Jan 2022 (Start Value) and 31st Dec 2023 (End Value). Here ELT Data will submit 730 pipeline runs each for 01-01-2022, 02-01-2022, 03-01-2022, ....... 31-12-2023
Ignore the variable used for defining the folder format or specify a pattern if you want a separate folder nomenclature for historical load.
Save the pipeline and ELT Data will run the Invoices pipeline for 730 different dates.
The 730 pipeline runs will run sequentially. This is avoid any race conditions between different pipeline runs acting on the same data.
The dedupe logic and the destination will be picked up from the Invoices Pipeline configuration.
Historical loads are usually long running processes. Please make sure you allocate enough time and capacity while running historical loads.